Introduction
Neural Style Transfer (NST) is a fascinating application of computer vision. The ability to separate and recombine the content and style of images using perceptual loss opens new possibilities for how we can use neural networks. In this project, I explored both the original NST algorithm and real-time style transfer using a feed-forward network.
The core idea behind NST is that deep convolutional networks trained for image classification learn hierarchical representations that can separate content from style. By using pre-trained VGG networks, we can extract perceptual features that capture the essence of an image’s content and style separately, enabling us to optimize a new image to match both and thus transfer the style of one image to another.

Mathematical Foundation
Perceptual Loss and VGG Features
The key insight of Neural Style Transfer lies in the observation that convolutional neural networks trained for image classification learn hierarchical feature representations that naturally separate content from style. The VGG network, pre-trained on ImageNet, serves as our feature extractor.
For a given image $\mathbf{x}$, let $\mathbf{F}^l$ be the feature maps at layer $l$ of the VGG network. The content representation is captured by the feature activations themselves, while the style representation is encoded in the correlations between different feature maps.
Content Loss
The content loss measures the difference between the feature representations of the content image and the generated image:
Where:
- $\mathbf{F}^l$ are the feature maps of the generated image at layer $l$
- $\mathbf{P}^l$ are the feature maps of the content image at layer $l$
Style Loss
The style loss captures the texture and artistic style by comparing the Gram matrices of the feature maps:
Where:
- $G^l$ is the Gram matrix of the generated image at layer $l$
- $A^l$ is the Gram matrix of the style image at layer $l$
- $N$ is the number of feature maps, $M$ is the size of each feature map
Total Loss
The total loss combines both content and style losses with weighting factors:
Where $\alpha$ and $\beta$ control the relative importance of content vs. style preservation.
Implementation details
1. Optimization of an image to match the style of another image
The original approach treats style transfer as an optimization problem. Starting from either a random noise image or the content image, we iteratively update the image to minimize the total loss defined previously.
The VGG layers chosen for the loss computation were the same ones used in the original paper.
A total variation regularization term was added to the loss to prevent the generated image from becoming too noisy.
I manually tuned the hyperparameters so that the content and style losses were balanced after a few iterations.
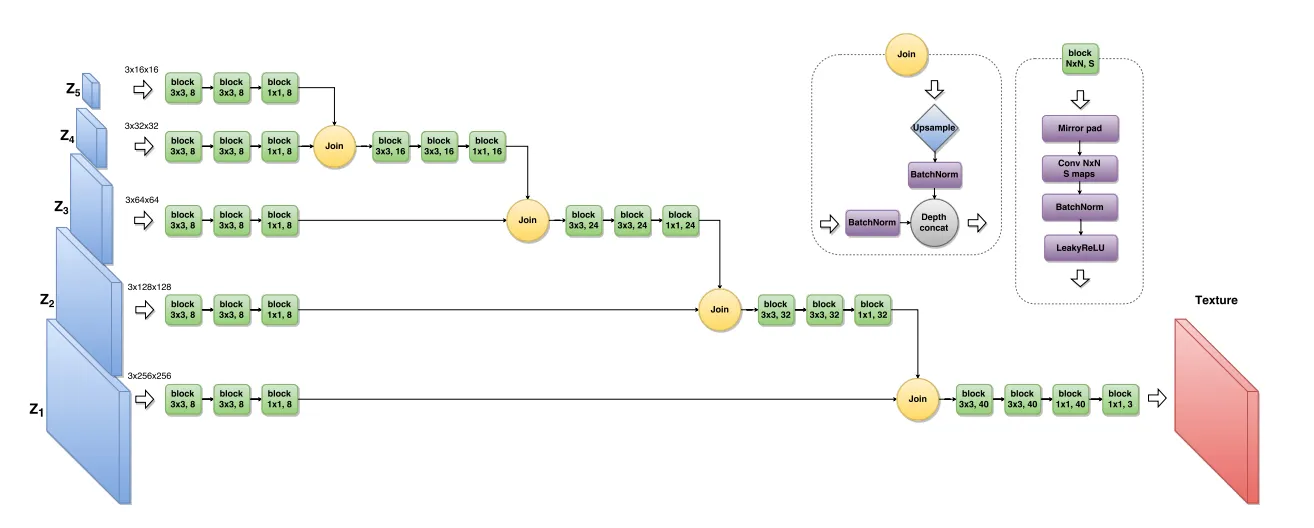
2. Feed-Forward Neural Style Transfer
The optimization-based approach requires hundreds of iterations per image. Fast NST addresses this limitation by training a feed-forward network that can generate stylized images in a single forward pass. The neural network takes the content image as input and outputs the stylized image directly.
Thoughts
This project marked a significant milestone in my deep learning journey. Implementing Neural Style Transfer directly from research papers taught me several valuable lessons:
Technical lessons
-
Playing with models and optimization: This project taught me that we can actually use models and optimization as we want with whatever pre-trained layer and whatever loss.
-
Perceptual Loss and Deep learning: The concept of using pre-trained networks as feature extractors to construct a loss is fascinating. It suddenly broadens the scope of what we can do with neural networks.
-
Optimization vs. Inference: Optimizing a model to directly minimize the loss is also very exciting. In other words, we accept spending more time beforehand to train a model in order to achieve real-time inference.
Research Skills
-
Paper Implementation: This was my first experience implementing algorithms directly from research papers without tutorials, which significantly improved my confidence in reading and implementing academic literature.
-
Debugging Complex Systems: I encountered a lot of bugs during this project, so I learned to systematically troubleshoot deep learning pipelines.
-
Hyperparameter tuning: I found it very interesting to visually observe the impact of hyperparameters on the output image. Everything felt much more concrete and intuitive.
References
-
Gatys, L. A., Ecker, A. S., & Bethge, M. (2015). A neural algorithm of artistic style. arXiv preprint arXiv:1508.06576. Link
-
Ulyanov, D., Lebedev, V., Vedaldi, A., & Lempitsky, V. (2016). Texture networks: Feed-forward synthesis of textures and stylized images. arXiv preprint arXiv:1603.03417. Link
-
Previous
French Robotic Cup - Autonomous Robot Development -
Next
Quick, Draw! Competition at Automatants