Introduction
This blog post details my experience winning the Automatants Quickdraw! competition on imbalanced image classification. This competition was an excellent opportunity to apply everything I had learned over a year of deep learning study and practice, and to experiment with a broad range of computer vision techniques on a challenging imbalanced dataset.
The competition was organized by Automatants, the AI student organization at CentraleSupélec. Many thanks to Thomas Lemercier for leading the organization and to Loïc Mura for hosting the contest.
For more details and the full code, see my GitHub repository.
Dataset and Competition Rules
The competition dataset was a subset of the Google Quick, Draw! dataset, which consists of 28x28 pixel black-and-white sketches. For the competition, we were given drawings from 100 classes, but with a severe class imbalance: the first class had 1,000 images, the second had 990, the third 980, and so on, down to just 10 images for the last class. The test set, in contrast, was balanced and contained 100,000 images.

Some of the competition rules made the challenge even more interesting:
- Teams could have up to three participants.
- Pre-trained models were forbidden; you could not fine-tune models trained on external data.
- Only the provided data could be used: no external data since it was easy to find the full dataset online.
- Each team was limited to a total of 10 submissions during whole the competition, meaning that we had to be careful about the quality of our submissions.
Approach and Techniques
Solving highly imbalanced classification tasks is a classic challenge in machine learning. With such an unbalanced training set and a large, balanced test set, it was clear that clever strategies would be required to win the competition. Below is a breakdown of the key techniques and experiments I conducted.
Data Augmentation
One of the most effective ways to fight data imbalance is to artificially increase the diversity of underrepresented classes. I employed a mix of basic data augmentation techniques: random rotations, flips, shifts, and small distortions. While more advanced augmentations like CutMix, Mixup, or Random Erasing are powerful, I found them less suited for this simple, small-scale sketch data, and more challenging to tune in time for the competition.
References:
- Perez, L., & Wang, J. (2017). The Effectiveness of Data Augmentation in Image Classification using Deep Learning. arXiv preprint arXiv:1712.04621. PDF
- Zhang, H., Cisse, M., Dauphin, Y. N., & Lopez-Paz, D. (2017). mixup: Beyond Empirical Risk Minimization. arXiv preprint arXiv:1710.09412. PDF
- Zhong, Z., Zheng, L., Kang, G., Li, S., & Yang, Y. (2017). Random Erasing Data Augmentation. arXiv preprint arXiv:1708.04896. PDF
- Yun, S., Han, D., Oh, S. J., Chun, S., Choe, J., & Yoo, Y. (2019). CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. Proceedings of the IEEE International Conference on Computer Vision (ICCV), 6023–6032. PDF
Model Architectures
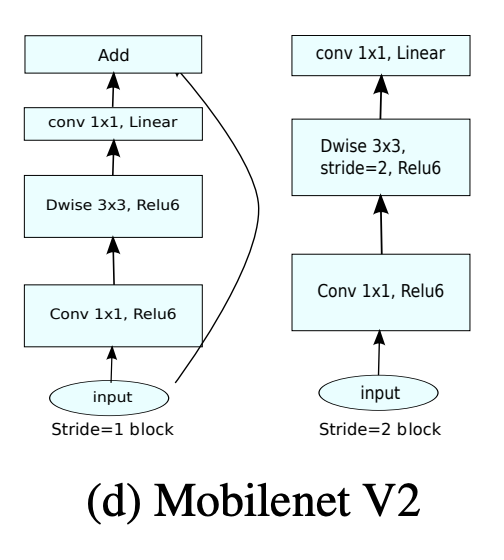
Given limited computational resources, I focused on lightweight but effective architectures. My main choice was MobileNetV2 which was known to be both fast and efficient, and surprisingly powerful even on small datasets. I also experimented with classic CNNs and ResNet networks, but MobileNetV2 consistently offered the best trade-off between performance and training speed.
References:
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep Residual Learning for Image Recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–778. PDF
- Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., & Chen, L.-C. (2018). MobileNetV2: Inverted Residuals and Linear Bottlenecks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 4510–4520. PDF
Regularization
Overfitting was a major issue. To prevent it, I explored a range of regularization techniques:
- Weight decay: Prevents weights from growing too large and forces the network to learn more robust features.
- Label smoothing: Softens the target labels, making the model less confident and often more generalizable.
- Dropout: Both classic and spatial dropout, plus stochastic depth, which randomly drops layers during training.
- Early stopping: Halts training when validation accuracy plateaus to avoid overfitting.
References:
- Müller, R., Kornblith, S., & Hinton, G. (2019). When Does Label Smoothing Help? Advances in Neural Information Processing Systems, 32. PDF
- Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: A Simple Way to Prevent Neural Networks from Overfitting. Journal of Machine Learning Research, 15(1), 1929–1958. PDF
- Li, X., Wang, W., Hu, X., & Yang, J. (2018). Understanding the Disharmony between Dropout and Batch Normalization by Variance Shift. arXiv preprint arXiv:1801.05134. PDF
- Huang, G., Sun, Y., Liu, Z., Sedra, D., & Weinberger, K. Q. (2016). Deep Networks with Stochastic Depth. European Conference on Computer Vision (ECCV), 646–661. arXiv
Feature Extraction and Classical ML
To see if classical ML algorithms could help, I extracted features from trained MobileNets and fed them into linear discriminant analysis (LDA) and gradient boosting classifiers. Unfortunately, these models didn’t match the performance of end-to-end MobileNets. This was likely because the high-level features learned by MobileNet are highly specialized, and classical methods lacked the flexibility to make use of them fully.
Reference:
- Yosinski, J., Clune, J., Bengio, Y., & Lipson, H. (2014). How transferable are features in deep neural networks? Advances in Neural Information Processing Systems, 27, 3320–3328. PDF
Semi-Supervised Learning: Noisy Student Training
The dataset’s labeled training set was half the size of the test set, simulating real-world scenarios where annotations are expensive. To leverage the large unlabeled test set, I looked into semi-supervised learning. In particular, I used the Noisy Student method which works as follows:
- Train a model on labeled data with added noise (dropout, data augmentation).
- Generate pseudo-labels for the unlabeled data using the trained model.
- Filter pseudo-labels by confidence thresholding.
- Retrain a new model on both labeled and high-confidence pseudo-labeled data.
This approach allowed me to effectively double the training data and gain a significant accuracy boost.
Reference:
- Xie, Q., Luong, M.-T., Hovy, E., & Le, Q. V. (2020). Self-training with Noisy Student improves ImageNet classification. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 10687–10698. PDF
Few-Shot Learning
I wanted to experiment with few-shot learning methods, particularly for the rarest classes, but ran out of time before making any progress. In the future, using a few-shot meta-learning algorithm like Relation Networks on the top K predictions from MobileNet could further improve rare class accuracy.
Reference:
- Sung, F., Yang, Y., Zhang, L., Xiang, T., Torr, P. H. S., & Hospedales, T. M. (2018). Learning to Compare: Relation Network for Few-Shot Learning. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1199–1208. PDF
Ensemble Methods
As the final push to boost accuracy, I combined the predictions of my best models using simple and weighted voting. I also experimented with meta-learners (stacked ensembles), but the best results came from a straightforward ensemble of six MobileNets, each trained using different seeds and regularizations. Distillation (training a smaller model to mimic the ensemble) would have been a promising next step if time had allowed.
Weighted Loss
Although I primarily used data augmentation to handle imbalance, another effective strategy is to use a weighted loss function that penalizes mistakes on rare classes more heavily. I didn’t use this approach due to time constraints and because my augmentation pipeline proved sufficient, but it remains a powerful alternative.
Results and Reflections
Best Model:
My top-performing solution was an ensemble of six MobileNets, each trained with Noisy Student learning and heavy regularization. This combination delivered the highest accuracy on the balanced test set.
Key Takeaways:
- Model architecture mattered less than expected; MobileNetV2’s efficiency was a big win.
- Regularization was crucial to avoid overfitting in this small, imbalanced data regime.
- Ensemble methods consistently improved results.
- Semi-supervised learning with Noisy Student had a major positive impact, showing the value of leveraging unlabeled data.
- Experimentation was worth it. Even though some approaches (like classical ML with deep features, or meta-learned ensembles) didn’t pay off, they deepened my understanding and made the project more rewarding.
This competition was an amazing way to consolidate and challenge my deep learning skills, and it reaffirmed the importance of regularization, creative use of unlabeled data, and the value of systematic experimentation. I’m glad I prioritized learning and trying new ideas over simply tuning hyperparameters for incremental gains.
References
- Perez, L., & Wang, J. (2017). The Effectiveness of Data Augmentation in Image Classification using Deep Learning. arXiv preprint arXiv:1712.04621. PDF
- Zhang, H., Cisse, M., Dauphin, Y. N., & Lopez-Paz, D. (2017). mixup: Beyond Empirical Risk Minimization. arXiv preprint arXiv:1710.09412. PDF
- Zhong, Z., Zheng, L., Kang, G., Li, S., & Yang, Y. (2017). Random Erasing Data Augmentation. arXiv preprint arXiv:1708.04896. PDF
- Yun, S., Han, D., Oh, S. J., Chun, S., Choe, J., & Yoo, Y. (2019). CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. Proceedings of the IEEE International Conference on Computer Vision (ICCV), 6023–6032. PDF
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep Residual Learning for Image Recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–778. PDF
- Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., & Chen, L.-C. (2018). MobileNetV2: Inverted Residuals and Linear Bottlenecks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 4510–4520. PDF
- Müller, R., Kornblith, S., & Hinton, G. (2019). When Does Label Smoothing Help? Advances in Neural Information Processing Systems, 32. PDF
- Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: A Simple Way to Prevent Neural Networks from Overfitting. Journal of Machine Learning Research, 15(1), 1929–1958. PDF
- Li, X., Wang, W., Hu, X., & Yang, J. (2018). Understanding the Disharmony between Dropout and Batch Normalization by Variance Shift. arXiv preprint arXiv:1801.05134. PDF
- Huang, G., Sun, Y., Liu, Z., Sedra, D., & Weinberger, K. Q. (2016). Deep Networks with Stochastic Depth. European Conference on Computer Vision (ECCV), 646–661. PDF
- Yosinski, J., Clune, J., Bengio, Y., & Lipson, H. (2014). How transferable are features in deep neural networks? Advances in Neural Information Processing Systems, 27, 3320–3328. PDF
- Xie, Q., Luong, M.-T., Hovy, E., & Le, Q. V. (2020). Self-training with Noisy Student improves ImageNet classification. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 10687–10698. PDF
- Sung, F., Yang, Y., Zhang, L., Xiang, T., Torr, P. H. S., & Hospedales, T. M. (2018). Learning to Compare: Relation Network for Few-Shot Learning. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1199–1208. PDF