About Polygon Technologies
I spent six months at Polygon Technologies, a psychology startup based in Santa Monica, California. Polygon was trying something new: offering remote diagnostics for learning differences such as dyslexia and ADHD. The approach was innovative and ambitious, but after the 2023 tech downturn, the company unfortunately shut down.
For me, this internship was a chance to work on the intersection of AI, healthcare, and psychology and to experience the fast-paced environment of the U.S. startup ecosystem.
Project Overview
The core idea was simple but powerful: record the sessions between psychologists and patients, then use AI to help interpret what happens during the tests.
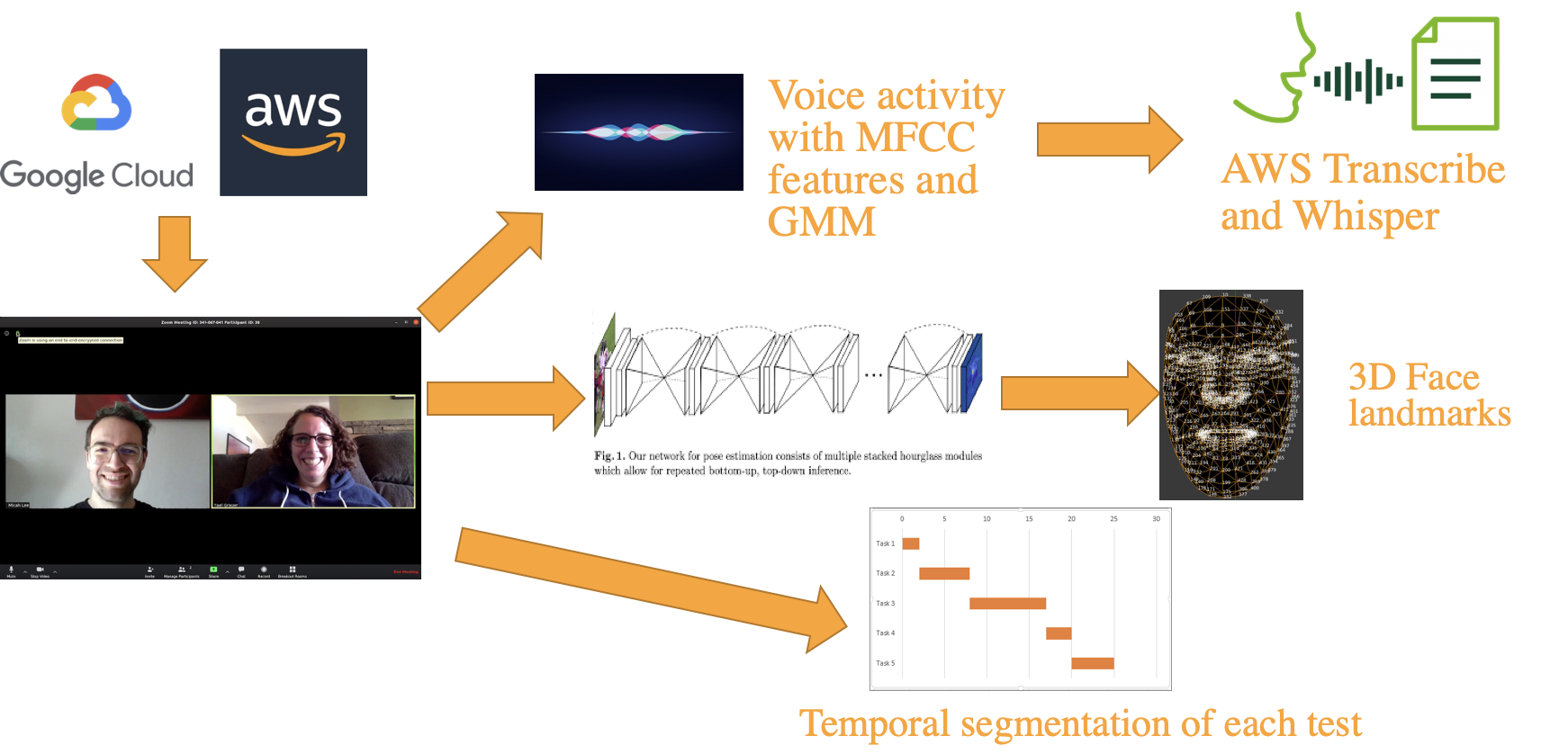
Instead of working directly on raw high-dimensional video, we would extract interpretable time series (face landmarks, speech activity, transcripts, etc.). This reduced complexity and, increased interpretability since it was a must in healthcare, where transparency is essential.
My Work
Refactoring and feature additions
Two predecessors had already worked on face landmarks detection and voice activity detection. My first task was to refactor their pipelines and normalize outputs into a common time series format (stored in Parquet).
I also added a speaker recognition module to separate patient vs. therapist, which was essential for later analysis.
Speech-to-text pipeline
We also wanted transcripts of the testing sessions. Early in my internship, Whisper had just been released!
I benchmarked Whisper against Amazon Transcribe and Google Speech-to-Text, using manually annotated transcripts and BLEU scores for evaluation. Whisper outperformed everything else (better accuracy, multilingual support, and free to use), so I integrated it into our pipeline.
Radford, A., Kim, J. W., Xu, T., Brockman, G., McLeavey, C., & Sutskever, I. (2023). Robust speech recognition via large-scale weak supervision. ICML 2023.
End-to-end feature extraction
The next step was to make the system run end-to-end.
- I migrated the existing Google Datalake into AWS S3 (to unify our infrastructure).
- I set up AWS Batch to process long Zoom videos (often 3+ hours).
- I integrated face landmarks detection, voice activity detection, and Whisper transcription into a single scalable pipeline.
Debugging was horrible since running the pipeline on 3-hour long videos took hours. We had about 20 patients with each 3 recordings of 3 hours and each time I could have an exception. By the end, we had a fully functional automated pipeline from raw video to structured time series.
Temporal segmentation
My final project was temporal segmentation: automatically detecting the start and end of each cognitive test during a session. I manually annotated part of the dataset and started experimenting with models. Unfortunately, time ran out before I could achieve conclusive results but it laid the foundation for the next iteration of the project.
Thoughts
This internship was much more than just technical work. I discovered how psychology practices operate, and how delicate it is to introduce AI into the diagnostic process. Technically, I learned a lot about speech processing, large-scale data pipelines, and AWS orchestration. I learned how challenging (and rewarding) it can be to build tools for healthcare, where reliability and interpretability matter as much as accuracy. Even though Polygon didn’t survive the 2023 downturn, my time there left a lasting impression. I got my first deep dive into the U.S. tech ecosystem: the fast pace, the ambition, and the mindset of people always ready to take risks and innovate.
-
Previous
Being a Machine Learning Consultant at Paris Digital Lab -
Next
Photogen AI - Founding a Startup on Diffusion Models