Project Overview
This project was part of the Bayesian Machine Learning course taught by Rémi Bardenet.
Together with Thomas Lemercier, I reimplemented the paper “Averaging Weights Leads to Wider Optima and Better Generalization” by Izmailov et al. (2019).
The core idea of Stochastic Weight Averaging (SWA) is to improve generalization by averaging model weights collected at different points along the SGD trajectory. Instead of keeping the final checkpoint, SWA computes a running average of weights, which is hypothesized to fall into a flatter region of the loss landscape. This property is empirically linked to better generalization.
How SWA Works
- Train a base model with SGD using a high constant or cyclical learning rate.
- Periodically save weights along the trajectory.
- Average the checkpoints to obtain the SWA model.
This process is computationally cheap and can be seen as an approximation of ensembling, but without training multiple models.
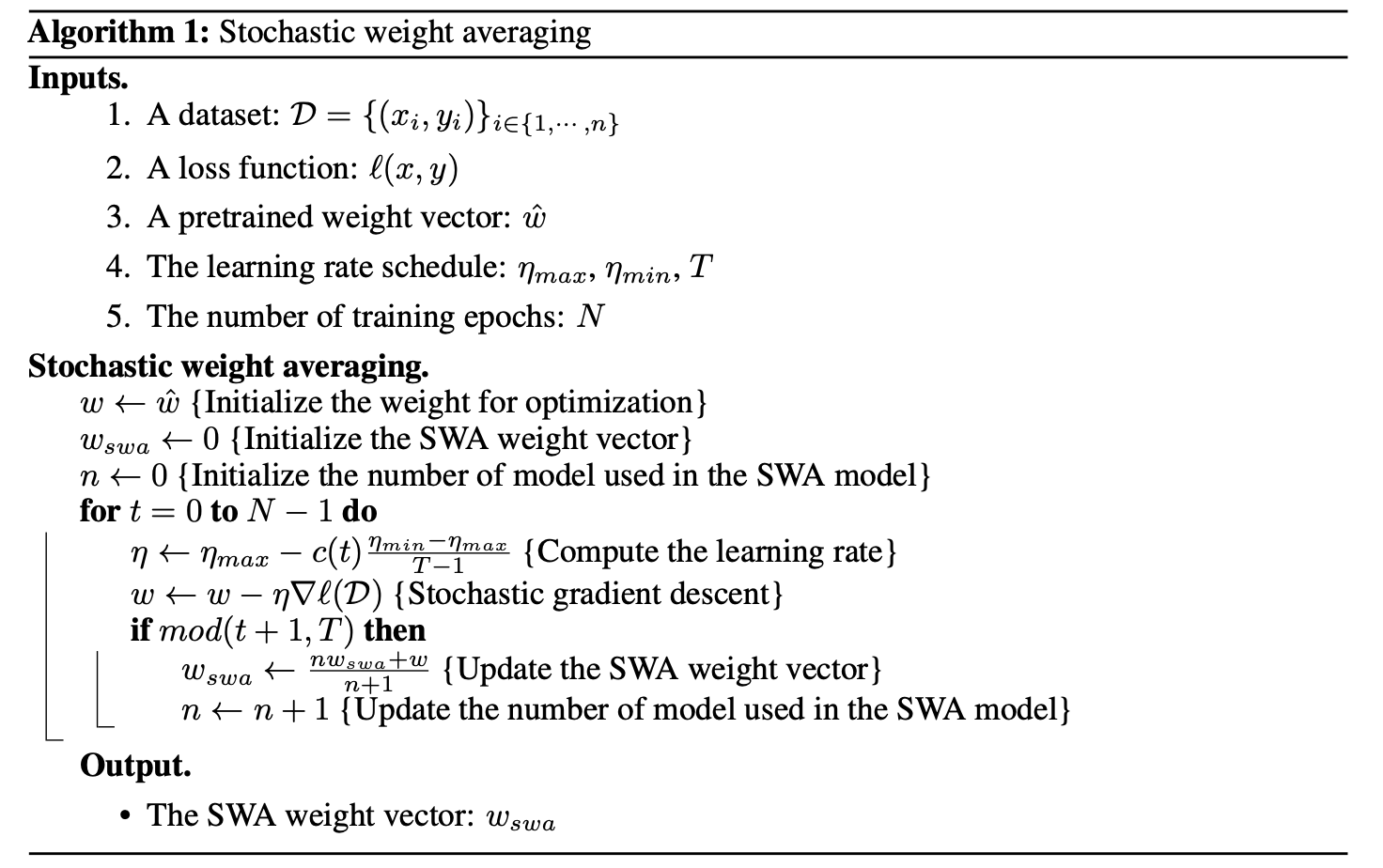
More details on the method are available in the report.
Experiments
We evaluated SWA across different domains:
- Synthetic regression (2D toy dataset, Friedman datasets).
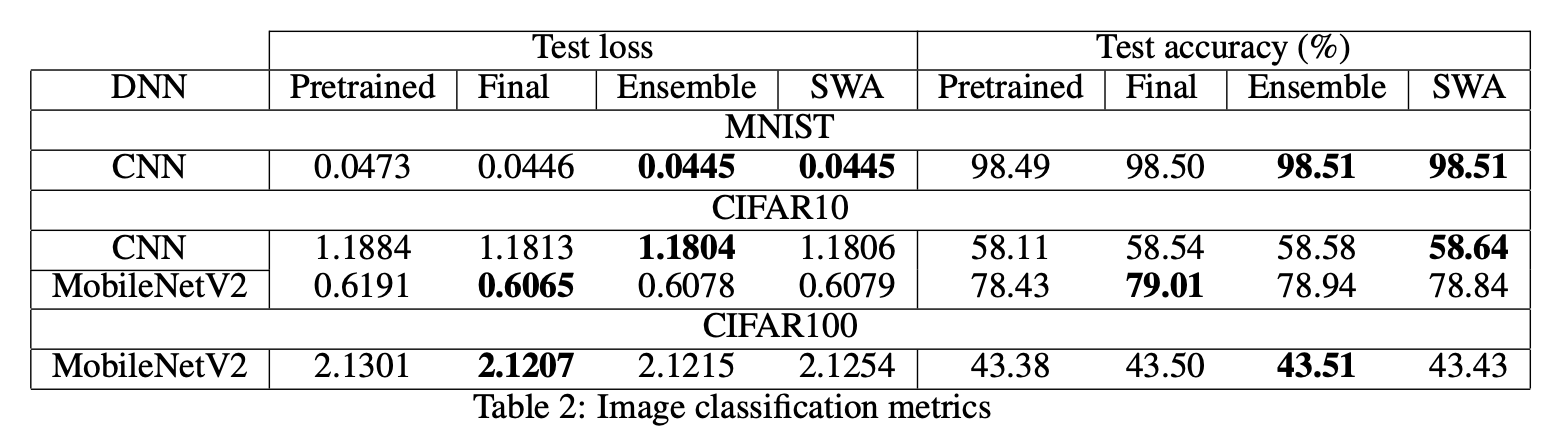
- Image classification with CNNs and MobileNet V2 on MNIST, CIFAR10, CIFAR100.
- Graph learning with a GCN on the CLUSTER dataset.
Here I will only show results on the image classification tasks—the trends were similar for the other datasets. Full details can be found in the report.
To examine the intuition behind SWA, we also visualized the loss landscapes of MobileNet V2 trained on CIFAR100:
| Loss landscape of MobileNet V2 on CIFAR100 |
|---|
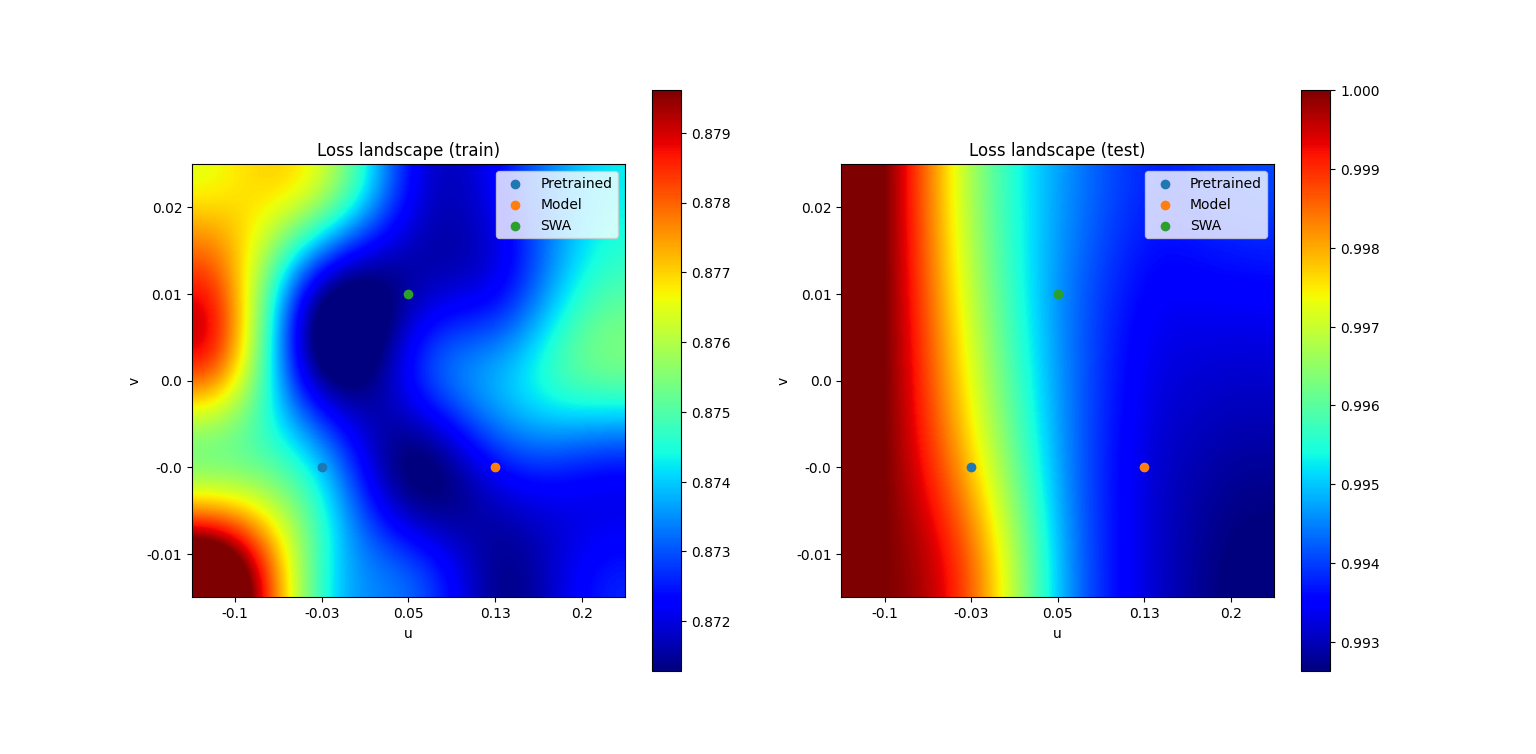 |
In contrast to the original paper, our experiments showed that SWA did not consistently improve performance over standard training. While the idea of averaging weights to approximate ensembling is elegant, our results suggest that SWA is not universally effective across datasets and architectures. The discrepancy with the original paper highlights the importance of reproducibility in deep learning research.
Documentation
References
- Izmailov, P., Podoprikhin, D., Garipov, T., Vetrov, D., & Wilson, A. G. (2019). Averaging weights leads to wider optima and better generalization.
- Garipov, T., Izmailov, P., Podoprikhin, D., Vetrov, D., & Wilson, A. G. (2018). Loss surfaces, mode connectivity, and fast ensembling of DNNs.