Project Overview
As part of the NLP course at Naver Labs Europe, we tackled aspect-based sentiment analysis.
The task is to classify a sentence’s sentiment (positive / negative / neutral) with respect to a specific aspect-term (e.g., food quality, service, ambiance).
This makes the task more challenging than standard sentiment analysis, since the same sentence may contain multiple aspects with different polarities.
Task Visualization

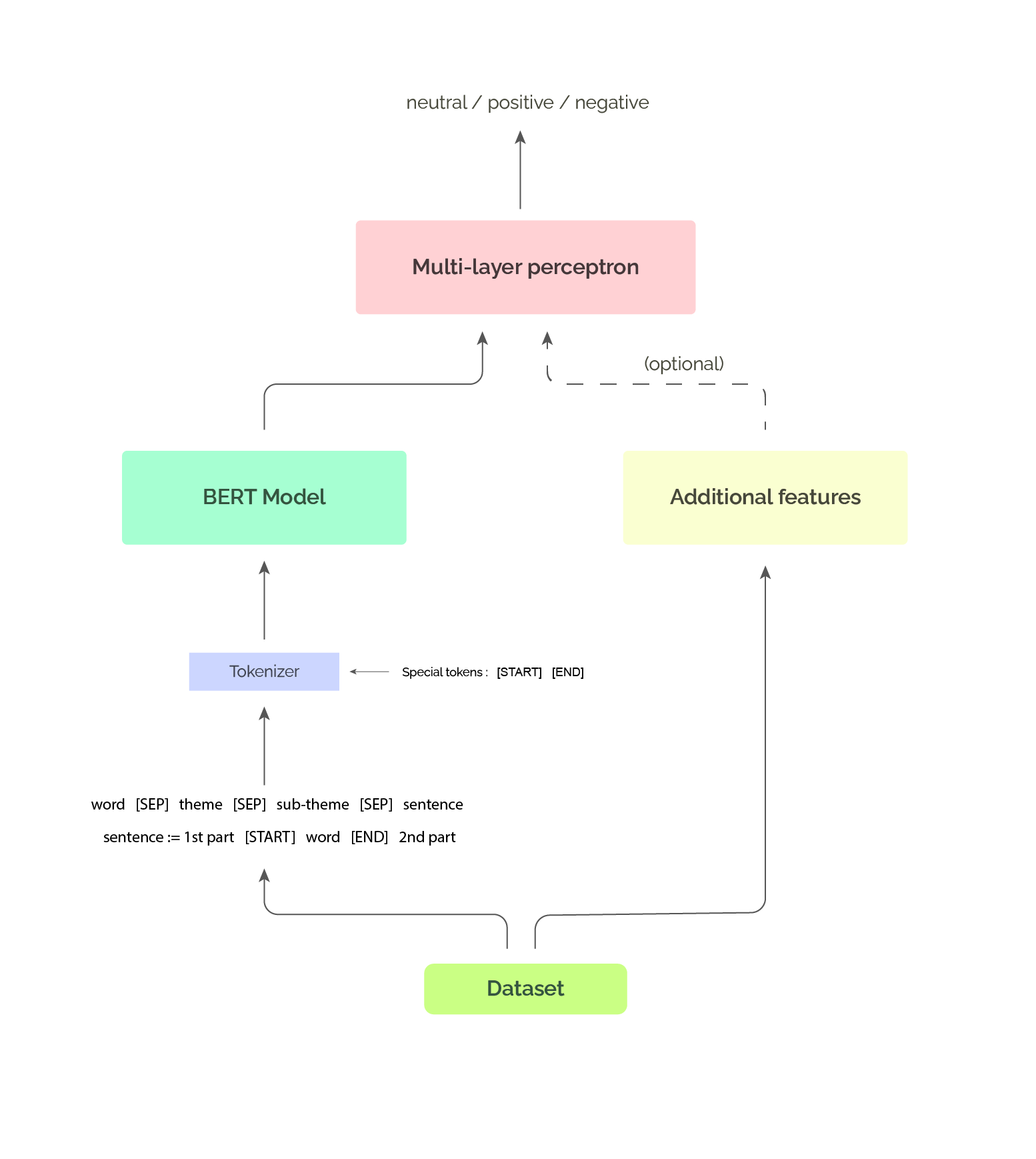
Model Architecture
We fine-tuned DistilBERT, a lightweight version of BERT, and adapted it to our task:
- Input Encoding: We used
[SEP]tokens to separate the aspect, sub-theme, and the sentence. - Aspect Markers: Two custom tokens
[START_WORD]and[END_WORD]were added around the aspect-term, helping the model focus on the relevant part of the text. - Categorical Features: Aspect categories and subcategories were one-hot encoded, then concatenated with DistilBERT’s pooled output through a small MLP classifier.
This design allowed the model to leverage both contextual embeddings and structured aspect information.
Data Augmentation
The dataset was small (~1500 training samples), so we applied aspect replacement augmentation:
- Replace an aspect-term with another term from the same category.
- This increased data diversity, though some generated sentences were nonsensical.
Results
We trained on 1503 samples and tested on 376 samples.
| Metric | Train set | Test set |
|---|---|---|
| Accuracy | 0.95 | 0.80 |
| F1 Score | 0.93 | 0.79 |
The model learned well but was prone to overfitting due to the dataset’s limited size. Dropout layers helped slightly, but adding complexity to the MLP often worsened results.
Code Repository
References
- Sanh, Victor, et al. DistilBERT: a distilled version of BERT. arXiv:1910.01108 (2019).
- Qiu, Xipeng, et al. Pre-trained models for NLP: A survey. (2020). [pdf]
- Acheampong, Adoma, et al. Comparative analyses of BERT, RoBERTa, DistilBERT, and XLNet for emotion recognition. (2020). [pdf]
-
Previous
Graph Neural Network Benchmark on Twitch Dataset -
Next
Nash Equilibrium Finding at Google DeepMind